栈和堆的数据结构详解:原理、区别与实际应用
在计算机科学领域,栈(Stack) 和 堆(Heap) 是两种非常基础且重要的数据结构。无论你是刚入门编程的新手,还是已经有几年经验的开发者,理解栈和堆的工作方式都至关重要——它们不仅是算法和数据结构课程的必修内容,更直接影响着程序的内存管理和运行效率。
这篇文章将从数据结构的角度,分别介绍栈和堆的定义、核心操作、典型应用,并对两者进行对比分析,帮助你建立起清晰的认知框架。
什么是栈(Stack)
栈是一种遵循 后进先出(LIFO, Last In First Out) 原则的线性数据结构。你可以把它想象成一摞盘子:每次只能往最上面放一个盘子,取的时候也只能从最上面拿。最后放进去的那个,反而最先被取出来。
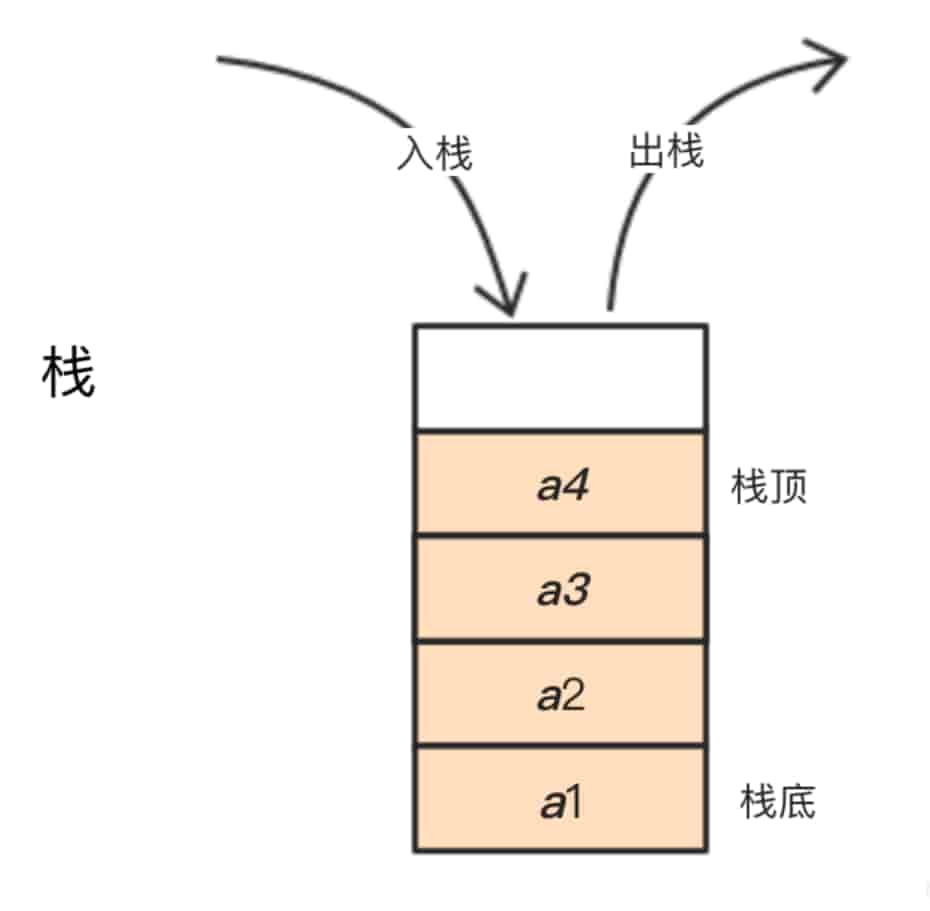
栈的核心操作
栈的操作非常简洁,主要包含以下几个:
| 操作 | 说明 |
|---|---|
| push | 将一个元素压入栈顶 |
| pop | 将栈顶元素弹出并返回 |
| peek / top | 查看栈顶元素,但不弹出 |
| empty | 判断栈是否为空 |
| size | 返回栈中元素的数量 |
这些操作的时间复杂度均为 O(1),这也是栈在性能上的一大优势。
栈的典型应用场景
栈在编程中的用途远比你想象的要广泛:
- 函数调用栈:程序在执行函数调用时,会把当前函数的上下文(局部变量、返回地址等)压入调用栈。函数返回时,再从栈顶弹出恢复现场。这就是为什么递归调用过深会导致"栈溢出(Stack Overflow)“错误。
- 表达式求值:编译器在解析算术表达式时,会借助栈来处理运算符的优先级,比如中缀表达式转后缀表达式。
- 括号匹配:判断一段代码中的括号是否正确配对,用栈来处理是最经典的做法。
- 浏览器前进 / 后退:浏览器的历史记录本质上就是两个栈在配合工作。
- 撤销操作(Undo):文本编辑器中的撤销功能,底层往往就是一个操作栈。
什么是堆(Heap)
堆是一种特殊的 完全二叉树 结构,它满足一个关键性质:每个节点的值都大于等于(或小于等于)其子节点的值。根据这个性质的不同,堆分为两种类型:
- 大根堆(Max-Heap):父节点的值 ≥ 所有子节点的值,根节点是整棵树中的最大值。
- 小根堆(Min-Heap):父节点的值 ≤ 所有子节点的值,根节点是整棵树中的最小值。
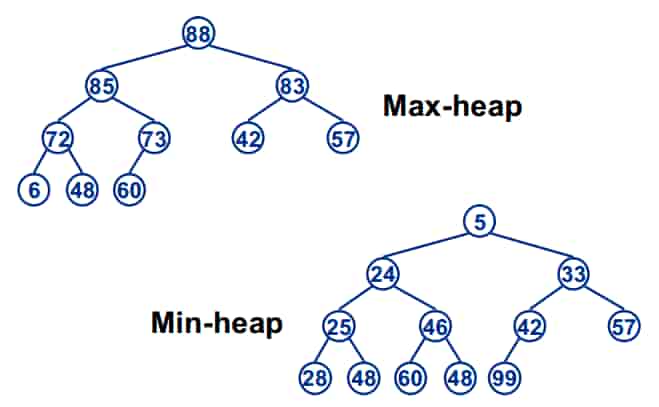
需要注意的是,堆虽然在逻辑上是一棵树,但在实际实现中,通常使用 数组 来存储。对于数组中下标为 i 的节点:
- 它的左子节点下标为
2*i + 1 - 它的右子节点下标为
2*i + 2 - 它的父节点下标为
(i - 1) / 2
这种数组表示法不需要额外的指针,内存利用率很高。
堆的核心操作
| 操作 | 说明 | 时间复杂度 |
|---|---|---|
| insert | 将元素插入堆中,放在末尾后向上调整(上浮) | O(log n) |
| extract-max / extract-min | 取出并删除根节点(最大或最小值),再向下调整(下沉) | O(log n) |
| peek | 查看根节点的值,不做删除 | O(1) |
| heapify | 将一个无序数组原地构建成堆 | O(n) |
| delete | 删除堆中指定元素,然后重新调整堆 | O(log n) |
堆的典型应用场景
- 优先队列:堆是实现优先队列最常见的底层结构。Go 语言标准库中的
container/heap包就是基于堆来实现的。 - 堆排序(Heap Sort):利用堆的特性可以实现一种时间复杂度为 O(n log n) 的排序算法,且不需要额外的存储空间。
- Top-K 问题:在海量数据中找出前 K 个最大(或最小)的元素,用堆来解决效率很高。
- 任务调度:操作系统的进程调度器经常使用优先队列来决定下一个执行哪个任务。
- 图算法:Dijkstra 最短路径算法和 Prim 最小生成树算法都依赖堆来优化性能。
栈和堆的对比
虽然栈和堆都是数据结构,但它们在设计理念和使用方式上有本质的不同:
| 对比维度 | 栈(Stack) | 堆(Heap) |
|---|---|---|
| 数据结构类型 | 线性结构 | 树形结构(完全二叉树) |
| 访问规则 | 后进先出(LIFO) | 按优先级访问(最大或最小值) |
| 插入 / 删除位置 | 仅在栈顶操作 | 在根节点和末尾操作,需要调整 |
| 典型时间复杂度 | push / pop 均为 O(1) | insert / extract 为 O(log n) |
| 底层实现 | 数组或链表 | 数组(逻辑上是树) |
| 主要用途 | 函数调用、表达式求值、回溯 | 优先队列、排序、Top-K 问题 |
另外,从内存管理的视角来看,“栈"和"堆"还有另一层含义:
- 栈内存(Stack Memory):由系统自动分配和释放,存储函数的局部变量和调用信息,空间有限但速度极快。
- 堆内存(Heap Memory):由程序在运行时动态申请,空间较大但需要手动管理(在 Go 等带 GC 的语言中由垃圾回收器负责回收)。
两者不要混淆——本文讨论的是 数据结构 层面的栈和堆,而非操作系统层面的内存区域划分。
常见问题
1. 栈和队列有什么区别?
栈是后进先出(LIFO),而队列是先进先出(FIFO, First In First Out)。栈只能在一端操作,队列则是一端入、另一端出。
2. 堆和二叉搜索树(BST)有什么不同?
二叉搜索树要求左子节点 < 父节点 < 右子节点,支持高效的查找操作。堆只要求父节点和子节点之间满足大小关系,不区分左右,因此堆不支持高效的任意查找,但在获取最值方面效率更高。
3. 为什么堆通常用数组而不是链表实现?
堆是完全二叉树,使用数组可以通过下标直接定位父子节点,不需要额外的指针开销,内存连续访问也对 CPU 缓存更友好,整体性能更优。
4. Go 语言中怎么使用堆?
Go 标准库提供了 container/heap 包。你只需要实现 heap.Interface 接口(包含 Len、Less、Swap、Push、Pop 五个方法),就可以使用 heap.Init、heap.Push、heap.Pop 等函数来操作堆。
5. 数据结构中的堆和内存中的堆是同一个概念吗?
不是。数据结构中的堆是一种完全二叉树,用于排序和优先队列;内存中的堆是操作系统分配给程序的一块动态内存区域,两者只是名字相同,本质完全不同。
总结
栈和堆是计算机科学中两种用途截然不同的数据结构:
- 栈 结构简单、操作高效,核心特征是后进先出。它在函数调用管理、表达式解析、括号匹配等场景中发挥着不可替代的作用。
- 堆 是一种基于完全二叉树的优先级结构,擅长快速获取最大值或最小值。优先队列、堆排序、Top-K 问题都是它的拿手好戏。
掌握这两种数据结构的原理和应用,不仅有助于你写出更高效的代码,也能让你在面试中从容应对相关的算法题。建议你在理解原理之后,动手用 Go 语言实现一遍栈和堆,加深印象。
如果你对栈和堆的数据结构还有疑问,或者在实际开发中遇到了相关的问题,欢迎在评论区留言交流,一起探讨学习~~~
版权声明
未经授权,禁止转载本文章。
如需转载请保留原文链接并注明出处。即视为默认获得授权。
未保留原文链接未注明出处或删除链接将视为侵权,必追究法律责任!
本文原文链接: https://fiveyoboy.com/articles/stack-heap-data-structures/
备用原文链接: https://blog.fiveyoboy.com/articles/stack-heap-data-structures/