Go 源码之 gorm 框架
看源码先看底层核心数据结构
在 Go 语言的数据库开发领域,GORM(Go Object Relational Mapping)框架绝对是绕不开的核心工具。
它以“简洁的 API、完整的 ORM 能力、多数据库适配”三大优势,成为开发者连接 MySQL、PostgreSQL 等数据库的首选。
GORM 的底层藏着精巧的架构设计——从模型映射到 SQL 生成,从事务管理到钩子函数,每一步都兼顾了易用性和扩展性。
今天,我们从源码角度拆解 GORM 的核心奥秘,带你看透它的运行逻辑。
一、源码解析
GORM 的核心能力依赖四大核心组件:DB(数据库连接容器)、Schema(模型映射核心)、Statement(SQL 构建器)、Dialector(数据库适配层)。
这四大组件协同工作,完成“模型 → SQL → 数据库交互 → 结果映射”的全流程。如下图

以下基于 GORM v2 版本(核心源码位于 gorm.io/gorm 包)解析。
(一)DB
DB:数据库连接的“总入口”。
*gorm.DB 是 GORM 对外提供的核心接口,封装了数据库连接池、配置信息、回调函数、数据库适配器等关键资源,所有数据库操作(查询、插入、事务)都通过它发起。
核心源码及注释如下:
// DB 是 GORM 数据库操作的核心结构体
type DB struct {
// 数据库连接池(不同数据库有不同实现,如 MySQL 的 sql.DB)
connPool ConnPool
// 数据库适配器(适配 MySQL、PostgreSQL 等不同数据库)
dialector Dialector
// 配置信息(如是否开启日志、超时时间、命名策略等)
config *Config
// 回调函数集合(如 BeforeCreate、AfterQuery 等生命周期钩子)
callbacks *Callbacks
// 当前 SQL 构建的上下文信息(包含模型、条件、SQL 语句等)
statement *Statement
// 错误信息(存储当前操作的错误)
error error
// 日志器(记录 SQL 执行、错误等日志)
logger logger.Interface
}
// Open 是初始化 DB 实例的入口方法
func Open(dialector Dialector, opts ...Option) (*DB, error) {
// 1. 初始化配置(合并默认配置和用户传入配置)
cfg := &Config{}
for _, opt := range opts {
opt(cfg)
}
// 2. 初始化日志器(默认使用默认日志器)
if cfg.Logger == nil {
cfg.Logger = logger.Default
}
// 3. 创建 DB 实例
db := &DB{
dialector: dialector,
config: cfg,
logger: cfg.Logger,
callbacks: &Callbacks{},
}
// 4. 初始化数据库连接池(通过适配器建立连接)
if err := db.initializeConnPool(); err != nil {
return nil, err
}
// 5. 初始化回调函数(注册默认的生命周期钩子)
db.callbacks.Initialize(db)
return db, nil
}
// 初始化数据库连接池
func (db *DB) initializeConnPool() error {
// 通过适配器的 Connect 方法建立连接,获取连接池
connPool, err := db.dialector.Connect(db)
if err != nil {
return err
}
db.connPool = connPool
return nil
}核心逻辑解析:DB 结构体通过“依赖注入”模式整合了连接池、适配器、回调等组件,Open 方法是初始化的核心——先合并配置,再通过 Dialector 建立数据库连接,最后初始化回调函数,为后续操作奠定基础。
Open 方法的执行流程如下图:

(二)Schema
Schema:模型与数据库表的“映射桥梁”。
GORM 的核心能力是“ORM 映射”——将 Go 结构体(模型)映射为数据库表,将结构体字段映射为表字段。
Schema 结构体就是这一映射逻辑的核心载体,负责解析模型标签(如 gorm:"primaryKey")、提取表结构信息。核心源码及注释如下:
// Schema 存储模型与数据库表的映射信息
type Schema struct {
// 模型对应的结构体类型(如 *User)
Type reflect.Type
// 表名(默认是结构体名复数形式,可通过标签自定义)
Table string
// 主键字段信息
PrimaryFields []*Field
// 所有字段的映射信息(key 是字段名,value 是字段详情)
Fields map[string]*Field
// 字段名到数据库列名的映射(处理命名策略,如蛇形命名)
Columns map[string]string
// 数据库列名到字段名的反向映射
ColumnFields map[string]*Field
// 模型的关联信息(如 HasOne、BelongsTo 等)
Relationships map[string]*Relationship
}
// Field 存储结构体字段与数据库列的映射信息
type Field struct {
// 结构体字段名(如 ID、Name)
Name string
// 数据库列名(如 id、user_name,受命名策略影响)
Column string
// 字段类型(如 int、string)
Type reflect.Type
// 主键标识
PrimaryKey bool
// 自增标识
AutoIncrement bool
// 非空标识
NotNull bool
// 字段标签信息(如 gorm:"size:255")
Tag Settings
// 字段的值(运行时存储字段的具体值)
Value reflect.Value
}
// Parse 是解析模型为 Schema 的核心方法
func Parse(dialector Dialector, model interface{}, opts ...SchemaOption) (*Schema, error) {
// 1. 获取模型的反射类型(支持指针或值类型)
typ := reflect.Indirect(reflect.ValueOf(model)).Type()
schema := &Schema{
Type: typ,
Fields: make(map[string]*Field),
Columns: make(map[string]string),
ColumnFields: make(map[string]*Field),
Relationships: make(map[string]*Relationship),
}
// 2. 应用配置(如自定义表名、命名策略)
for _, opt := range opts {
opt(schema)
}
// 3. 解析表名(默认使用命名策略,如 User → users)
if schema.Table == "" {
schema.Table = dialector.NamingStrategy().TableName(typ.Name())
}
// 4. 解析结构体字段,生成 Field 信息
for i := 0; i < typ.NumField(); i++ {
structField := typ.Field(i)
// 跳过未导出字段(首字母小写)
if structField.PkgPath != "" {
continue
}
// 解析字段标签和属性,生成 Field 实例
field, err := parseField(dialector, schema, structField)
if err != nil {
return nil, err
}
schema.Fields[field.Name] = field
schema.Columns[field.Name] = field.Column
schema.ColumnFields[field.Column] = field
// 标记主键字段
if field.PrimaryKey {
schema.PrimaryFields = append(schema.PrimaryFields, field)
}
}
// 5. 解析模型关联关系(如 HasMany)
if err := schema.parseRelationships(dialector); err != nil {
return nil, err
}
return schema, nil
}核心逻辑解析:Schema 的 Parse 方法通过反射解析模型结构体,核心做了三件事:
-
处理表名(应用命名策略);
-
解析结构体字段,提取标签信息(如
primaryKey、autoIncrement)生成Field实例; -
解析关联关系(如
HasOne)。这一步是“结构体 → 表结构”的关键。
(三)Statement
Statement:SQL 构建的“核心引擎”。
当我们调用 db.Where("id = ?", 1).Find(&user) 时,底层是通过 Statement 结构体逐步构建 SQL 语句的。
Statement 封装了查询条件、模型信息、SQL 语句、绑定参数等,是 GORM 生成 SQL 的核心载体。
核心源码及注释如下:
// Statement 存储 SQL 构建和执行的上下文信息
type Statement struct {
// 关联的 DB 实例
DB *DB
// 模型的 Schema 信息
Schema *Schema
// 当前操作的模型实例(如 &User{})
Model interface{}
// SQL 语句(如 SELECT * FROM users WHERE id = ?)
SQL string
// SQL 绑定参数(如 [1],替换 SQL 中的 ?)
Vars []interface{}
// 当前操作类型(如 Create、Query、Update、Delete)
Op Op
// 查询条件(存储 Where、Having 等条件)
Conditions []Condition
// 选择的字段(如 SELECT id, name FROM ...)
Selects []string
// 排除的字段(如 SELECT * EXCEPT password FROM ...)
Omits []string
// 排序条件(如 ORDER BY id DESC)
Orders []OrderBy
// 分页信息(如 LIMIT 10 OFFSET 20)
Limit, Offset int
// 关联查询信息
Relationships []*Relationship
}
// Build 是构建 SQL 语句的核心方法
func (stmt *Statement) Build(clauses ...Clause) error {
// 1. 初始化 Schema(若未设置,从 Model 解析)
if stmt.Schema == nil && stmt.Model != nil {
schema, err := Parse(stmt.DB.dialector, stmt.Model)
if err != nil {
return err
}
stmt.Schema = schema
}
// 2. 应用默认子句(根据操作类型,如 Query 对应 SELECT 子句)
defaultClauses := getDefaultClauses(stmt.Op)
clauses = append(defaultClauses, clauses...)
// 3. 遍历子句,构建 SQL 片段
for _, clause := range clauses {
if err := clause.Build(stmt); err != nil {
return err
}
}
// 4. 处理 SQL 美化(如添加空格、换行,仅开发环境)
if stmt.DB.config.PrepareStmt || stmt.DB.config.DisableAutomaticPing {
stmt.SQL = stmt.DB.dialector.Quote(stmt.SQL)
}
return nil
}
// 以 Where 条件为例,构建查询条件子句
func (c Condition) Build(stmt *Statement) error {
// 1. 解析条件(支持 map、struct、字符串等多种形式)
expr, vars, err := c.Expr.Build(stmt)
if err != nil {
return err
}
// 2. 将条件添加到 SQL 中(如 WHERE id = ?)
if stmt.SQL == "" {
stmt.SQL = fmt.Sprintf("WHERE %s", expr)
} else {
stmt.SQL = fmt.Sprintf("%s AND %s", stmt.SQL, expr)
}
// 3. 添加绑定参数
stmt.Vars = append(stmt.Vars, vars...)
return nil
}核心逻辑解析:Statement 的 Build 方法是 SQL 生成的核心,通过“子句(Clause)”机制构建完整 SQL——不同操作(如查询、插入)对应不同默认子句,再结合 Where、Select 等条件子句,逐步拼接 SQL 片段并绑定参数,最终生成可执行的 SQL 语句。
(四)Dialector
Dialector:数据库适配的“兼容层”。
GORM 支持 MySQL、PostgreSQL、SQLite 等多种数据库,这一兼容性依赖 Dialector 接口实现。Dialector 定义了数据库连接、SQL 生成、命名策略等核心接口,不同数据库通过实现该接口实现适配。核心源码及注释如下:
// Dialector 数据库适配器接口,定义数据库相关的核心能力
type Dialector interface {
// 建立数据库连接,返回连接池
Connect(*DB) (ConnPool, error)
// 获取数据库名称(如 mysql、postgres)
Name() string
// 命名策略(表名、列名的命名规则,如蛇形命名)
NamingStrategy() schema.Namer
// 构建 SQL 子句(如 LIMIT、OFFSET 在不同数据库的差异)
BuildClause(clause Clause, stmt *Statement) error
// 处理数据类型映射(如 Go 的 time.Time 对应数据库的 DATETIME)
DataTypeOf(field *schema.Field) string
// 检查错误类型(如判断是否为唯一键冲突错误)
TranslateError(err error) error
}
// 以 MySQL 适配器为例,实现 Dialector 接口
type MySQL struct {
// MySQL 连接字符串(如 root:123456@tcp(127.0.0.1:3306)/test?charset=utf8mb4)
DSN string
// 命名策略(默认蛇形命名)
Namer schema.Namer
// 其他配置(如超时时间、是否开启预处理)
Config Config
}
// Connect 实现 Dialector 接口,建立 MySQL 连接
func (m MySQL) Connect(db *DB) (ConnPool, error) {
// 1. 调用标准库 sql.Open 建立连接
sqlDB, err := sql.Open("mysql", m.DSN)
if err != nil {
return nil, err
}
// 2. 应用配置(如设置连接池大小、超时时间)
if err := sqlDB.Ping(); err != nil {
return nil, err
}
sqlDB.SetMaxOpenConns(m.Config.MaxOpenConns)
sqlDB.SetMaxIdleConns(m.Config.MaxIdleConns)
sqlDB.SetConnMaxLifetime(m.Config.ConnMaxLifetime)
return sqlDB, nil
}
// DataTypeOf 实现 Dialector 接口,映射 Go 类型到 MySQL 类型
func (m MySQL) DataTypeOf(field *schema.Field) string {
switch field.Type.Kind() {
case reflect.Int, reflect.Int64:
if field.AutoIncrement {
return "int AUTO_INCREMENT"
}
return "int"
case reflect.String:
if size, ok := field.Tag.Get("size"); ok {
return fmt.Sprintf("varchar(%s)", size)
}
return "varchar(255)"
case reflect.Bool:
return "tinyint(1)"
case reflect.Struct:
if field.Type == reflect.TypeOf(time.Time{}) {
return "datetime"
}
}
return ""
}核心逻辑解析:Dialector 接口通过“面向接口编程”实现数据库兼容——不同数据库实现自身的 Connect(建立连接)、DataTypeOf(类型映射)等方法,GORM 核心逻辑无需关心具体数据库类型,只需调用接口方法即可,实现“一次编码,多数据库适配”。
(五)Config
Config 结构是 gorm 框架的配置结构,包含了 DB 的所有配置,核心源码及示例如下:
// Config GORM config
type Config struct {
// GORM perform single create, update, delete operations in transactions by default to ensure database data integrity.You can disable it by setting `SkipDefaultTransaction` to true
// 为了确保数据一致性,GORM 会在事务里执行写入操作(创建、更新、删除)。如果没有这方面的要求,您可以在初始化时禁用它。
// 系统的默认事务:我们的gorm连接到数据库后,我们所做的增删改查操作,只要是这种链式的,gorm会自动的帮我们以事务的方式给串联起来,保证数据的一致性
SkipDefaultTransaction bool
// NamingStrategy tables, columns naming strategy
// 表名命名策略,在使用AutoMigter时,会将model的名转小写并+s,SingularTable: true, // love表将是love,不再是loves,即可成功取消表明被加s,或者在model结构实现TableName()方法即可自定义表名
NamingStrategy schema.Namer
// FullSaveAssociations full save associations
// 在创建、更新记录时,GORM 会通过 Upsert 自动保存关联及其引用记录
FullSaveAssociations bool
// Logger 支持自定义logger实现
Logger logger.Interface
// NowFunc the function to be used when creating a new timestamp
// 更改创建时间使用的函数
NowFunc func() time.Time
// DryRun generate sql without execute
// 生成 SQL 但不执行,可以用于准备或测试生成的 SQL,参考 会话 获取详情
DryRun bool
// PrepareStmt executes the given query in cached statement
// PreparedStmt 在执行任何 SQL 时都会创建一个 prepared statement 并将其缓存,以提高后续的效率,参考 会话 获取详情
PrepareStmt bool
// DisableAutomaticPing
// 在完成初始化后,GORM 会自动 ping 数据库以检查数据库的可用性,若要禁用该特性,可将其设置为 true
DisableAutomaticPing bool
// DisableForeignKeyConstraintWhenMigrating
DisableForeignKeyConstraintWhenMigrating bool
// DisableNestedTransaction disable nested transaction
// 禁用嵌套事务;GORM 会使用 SavePoint(savedPointName),RollbackTo(savedPointName) 为你提供嵌套事务支持
DisableNestedTransaction bool
// AllowGlobalUpdate allow global update
AllowGlobalUpdate bool
// QueryFields executes the SQL query with all fields of the table
// 默认select * from,QueryFields=true的情况下,
QueryFields bool
// CreateBatchSize default create batch size
// 设置批量创建的最大数
CreateBatchSize int
// ClauseBuilders clause builder
ClauseBuilders map[string]clause.ClauseBuilder
// ConnPool db conn pool
ConnPool ConnPool
// Dialector database dialector
Dialector
// Plugins registered plugins
Plugins map[string]Plugin
// 回调函数,又称钩子函数
callbacks *callbacks
cacheStore *sync.Map
}(六)Session
Session 结构是 gorm 用来控制 DB 会话的核心结构,核心源码及注释如下:
// Session session config when create session with Session() method
// Seesion用来重新配置DB结构中的Config结构的
type Session struct {
DryRun bool
PrepareStmt bool
NewDB bool
SkipHooks bool
SkipDefaultTransaction bool
DisableNestedTransaction bool
AllowGlobalUpdate bool
FullSaveAssociations bool
QueryFields bool
Context context.Context
Logger logger.Interface
NowFunc func() time.Time
CreateBatchSize int
}(七)Processor
Processor 结构是用来定义一些钩子函数的,其中包含内置的一些 callback,核心源码及注释如下:
// 最终的sql处理器:1.model的处理;2.回写数据结构dest的处理;3.
type processor struct {
db *DB
Clauses []string
fns []func(*DB) // 将callbacks排序后的钩子函数
callbacks []*callback // 钩子函数
}
// 核心处理方法,基本上所有的操作最终都会走这个方法,注意,该方法内部没有具体的执行sql的代码,原因是该方法只会执行 钩子函数,
// 而gorm的操作sql的api如update,create,save等都是在初始化(Initialize)的时候默认注册了钩子函数
func (p *processor) Execute(db *DB) *DB {}callbacks 包下面包含全部gorm 自带的方法:
func RegisterDefaultCallbacks(db *gorm.DB, config *Config) { queryCallback := db.Callback().Query()
// 注册相应的查询方法
queryCallback := db.Callback().Query()
queryCallback.Register("gorm:query", Query)
queryCallback.Register("gorm:preload", Preload)
queryCallback.Register("gorm:after_query", AfterQuery)
queryCallback.Clauses = config.QueryClauses
}
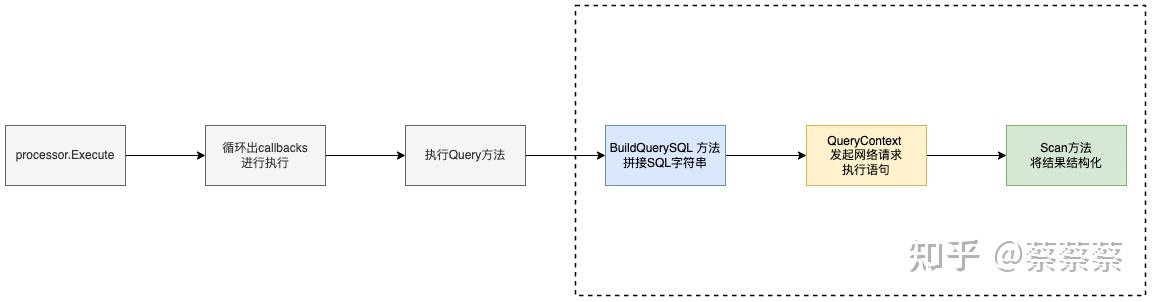
func Query(db *gorm.DB) {
if db.Error == nil {
// 1.构建查询的SQL
BuildQuerySQL(db)
// 2.真正对语句进行执行,并返回对应的Rows结果
if !db.DryRun && db.Error == nil {
rows, err := db.Statement.ConnPool.QueryContext(db.Statement.Context, db.Statement.SQL.String(), db.Statement.Vars...)
gorm.Scan(rows, db, 0)
}
}
}
func BuildQuerySQL(db *gorm.DB) {
// 核心构建语句,通过Build 拼接出对应的字符串
db.Statement.Build(db.Statement.BuildClauses...)
} 钩子函数的执行:
// 默认的钩子函数,如query,create,update,delete等
open()-->Initialize(db *gorm.DB)-->callbacks.RegisterDefaultCallbacks()-->callback.Register()
callback.Register():callback是*processor结构,表示指定类型(如create)处理器,Register()内部调用compile()会注册钩子函数到 *processor结构中的fns数组(最后执行的数据一次执行)
compile() 函数将注册的钩子函数进行排序操作,按照 before 还是after 添加在fns数组中默认钩子函数的前还说后
如:
// 我们手动注册一个 create的前置钩子函数,大概的流程为:open()执行后,db.fns数组中会存在一个默认的Create函数,前置钩子函数handler1会注册到fns数组的默认Create函数之前,fns变为[handler1,Create]
db.Callback().Create().Before("gorm:create").Register("gorm:auto_migrate", handler1)
// 后置钩子函数handler2会注册到fns数组的默认Create函数之后,fns变为[handler1,Create,handler2]
db.Callback().Create().After("gorm:create").Register("gorm:auto_migrate", handler2)
最终在*processor.Execute()方法中会遍历执行fns数组,从而达到拦截器(中间件)的作用二、核心 ORM 原理
GORM 的 ORM 能力本质是“将 Go 模型操作转换为数据库 SQL 操作”,核心包含三大流程:模型映射、SQL 生成、结果映射。
以下解析这三大流程的底层逻辑。
(一)模型映射
模型映射:结构体 → 表结构。
模型映射是 ORM 的基础,GORM 通过反射解析结构体及其标签,将其转换为数据库表结构。核心规则如下:
-
表名映射:默认使用结构体名的复数形式(如
User→users),可通过gorm:"table:user_info"标签自定义,或通过命名策略全局配置。 -
字段映射:默认使用字段名的蛇形命名(如
UserName→user_name),可通过gorm:"column:user_name"标签自定义;未导出字段(首字母小写)会被跳过。 -
属性映射:通过标签指定字段属性,如
gorm:"primaryKey"标记主键、gorm:"autoIncrement"标记自增、gorm:"not null"标记非空、gorm:"unique"标记唯一键。
示例:通过标签控制模型映射
// User 模型定义
type User struct {
// 主键,自增,列名自定义为 user_id
ID uint `gorm:"primaryKey;column:user_id;autoIncrement"`
// 非空,字符串类型,长度 50,列名 user_name
UserName string `gorm:"not null;size:50;column:user_name"`
// 非空,整数类型,列名 age
Age int `gorm:"not null;column:age"`
// 时间类型,自动记录创建时间(GORM 内置标签)
CreatedAt time.Time `gorm:"autoCreateTime;column:created_at"`
// 时间类型,自动记录更新时间(GORM 内置标签)
UpdatedAt time.Time `gorm:"autoUpdateTime;column:updated_at"`
}
// 解析后的表结构(MySQL)
// CREATE TABLE `users` (
// `user_id` int NOT NULL AUTO_INCREMENT,
// `user_name` varchar(50) NOT NULL,
// `age` int NOT NULL,
// `created_at` datetime NOT NULL,
// `updated_at` datetime NOT NULL,
// PRIMARY KEY (`user_id`)
// ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;(二)SQL 生成
SQL 生成:链式调用 → 可执行 SQL。
GORM 提供的链式调用(如 db.Where().Select().Limit().Find())本质是逐步给 Statement 结构体设置参数,最终通过 Build 方法生成 SQL。以查询操作为例,核心流程如下:
-
初始化 Statement:调用
Find方法时,GORM 会创建Statement实例,设置Op = Query(操作类型为查询),并解析模型生成Schema。 -
添加查询条件:调用
Where("age > ?", 18)时,会创建Condition实例,添加到Statement.Conditions中。 -
设置查询字段:调用
Select("user_id", "user_name")时,将字段名添加到Statement.Selects中。 -
设置分页信息:调用
Limit(10).Offset(20)时,设置Statement.Limit = 10、Statement.Offset = 20。 -
构建 SQL:调用
Build方法,根据Op = Query加载默认的SELECT、FROM子句,再结合Conditions、Limit等构建完整 SQL。
示例:链式调用生成 SQL 的过程
// 链式调用代码
var users []User
db.Select("user_id", "user_name").
Where("age > ?", 18).
Limit(10).
Offset(20).
Order("created_at DESC").
Find(&users)
// 底层 Statement 构建的 SQL 和参数
// SQL: SELECT user_id, user_name FROM users WHERE age > ? ORDER BY created_at DESC LIMIT ? OFFSET ?
// Vars: [18, 10, 20](三)结果映射
结果映射:数据库结果 → Go 模型。
SQL 执行完成后,GORM 需要将数据库返回的结果(如 sql.Rows)映射为 Go 模型实例。核心通过反射实现,流程如下:
-
获取结果列名:通过
rows.Columns()获取查询返回的列名(如user_id、user_name)。 -
创建值指针切片:根据列名从
Schema.ColumnFields中找到对应的模型字段,创建字段值的指针切片(用于接收数据库结果)。 -
扫描结果到指针切片:调用
rows.Scan()将数据库结果扫描到指针切片中。 -
赋值到模型实例:通过反射将指针切片中的值赋值到模型实例的对应字段中。
核心源码(简化版):
// ScanRows 将 sql.Rows 结果映射到模型切片
func (stmt *Statement) ScanRows(rows *sql.Rows, result interface{}) error {
// 1. 获取结果列名
columns, err := rows.Columns()
if err != nil {
return err
}
// 2. 解析结果的反射类型(如 []User)
resultVal := reflect.Indirect(reflect.ValueOf(result))
elemType := resultVal.Type().Elem()
// 3. 遍历结果行
for rows.Next() {
// 3.1 创建模型实例(如 &User{})
elem := reflect.New(elemType).Elem()
// 3.2 创建值指针切片(用于接收结果)
values := make([]interface{}, len(columns))
for i, col := range columns {
// 根据列名找到对应的模型字段
field := stmt.Schema.ColumnFields[col]
// 创建字段值的指针
values[i] = elem.FieldByName(field.Name).Addr().Interface()
}
// 3.3 扫描结果到指针切片
if err := rows.Scan(values...); err != nil {
return err
}
// 3.4 将模型实例添加到结果切片
resultVal.Set(reflect.Append(resultVal, elem))
}
return rows.Err()
}三、并发安全模型
gorm 框架是并发安全的,gorm 处理并发冲突的方法和 golang 的 context 相似,通过复制 db 结构解决;具体详见 clone的设计
四、调用链
这里以 create 函数作为示例,代码如下:
db.Table(tableName).Create(model)
// 调用链如下:
// var tx=db.Table(tableName)
// tx.callbacks.Create().Execute(tx)
// tx.callbacks ---> 钩子函数,open()内会调用Initialize()函数,注册gorm的操作sql的api如update,create,save等默认的钩子函数结构 *processor
// tx.callbacks.Create() 取到 create类型的*processor
// Execute(tx) 执行具体类型(如create类型的*processor)的钩子函数,具体的sql执行在钩子函数create中执行流程
常见问题
Q1. 模型映射失败,表字段未生成或字段不匹配?
常见原因及解决方法:
-
字段未导出:结构体字段首字母小写会被 GORM 忽略,需改为首字母大写(如
userName→UserName)。 -
标签错误:标签格式错误(如少写引号、拼写错误),需检查标签格式(如
gorm:"primaryKey"而非gorm:primaryKey)。 -
命名策略影响:默认蛇形命名,若表字段是驼峰命名,需通过
column标签指定(如gorm:"column:userName")。 -
未执行自动迁移:需调用
db.AutoMigrate(&User{})生成表结构。
Q2. 事务操作时,修改数据未生效或自动回滚?
常见原因及解决方法:
-
使用原始 db 实例而非 tx 实例:事务内操作必须使用
db.Begin()返回的tx实例,否则操作不在事务内。 -
未提交事务:事务内操作完成后未调用
tx.Commit(),导致事务自动回滚。 -
操作后未检查错误直接提交:需在每个操作后检查
tx.Error,错误时调用tx.Rollback()。 -
数据库不支持事务:如 MySQL 的 MyISAM 引擎不支持事务,需改为 InnoDB 引擎。
Q3. 查询性能低,如何优化?
优化方向:
-
避免查询不必要的字段:使用
Select指定需要的字段(如db.Select("id", "user_name").Find(&users)),减少数据传输量。 -
添加索引:通过
gorm:"index"标签给查询条件字段添加索引(如Age int `gorm:"index"`)。 -
避免 N+1 查询问题:关联查询时使用
Preload预加载关联数据(如db.Preload("Orders").Find(&users)),而非循环查询。 -
使用原生 SQL:复杂查询场景,使用
db.Raw()执行原生 SQL,避免 GORM 生成冗余 SQL。 -
开启预处理:在初始化时配置
PrepareStmt: true,缓存 SQL 语句,减少解析开销。
Q4. 钩子函数不执行,是什么原因?
常见原因及解决方法:
-
钩子函数签名错误:钩子函数必须是模型的方法,且签名正确(如
BeforeCreate签名为func (u *User) BeforeCreate(tx *gorm.DB) error),参数或返回值错误会导致不执行; -
模型是值类型而非指针类型:钩子函数的接收者必须是指针类型(如
*User),值类型会导致 GORM 无法修改模型字段且不执行钩子; -
使用了不触发钩子的方法:如
db.Exec("INSERT INTO ...")执行原生 SQL 不触发钩子,需使用db.Create()等 ORM 方法; -
钩子函数返回错误:若前一个钩子函数返回错误,后续钩子函数不会执行,需检查前序钩子的错误信息。
总结
GORM 框架的成功源于其“简洁 API 与强大底层设计的平衡”——通过 DB 结构体封装连接入口,Schema 实现模型与表的映射,Statement 构建 SQL,Dialector 实现多数据库适配,四大组件协同支撑起完整的 ORM 能力。
核心设计亮点:
-
接口抽象:通过
Dialector、ConnPool等接口实现高扩展性,便于适配新数据库或自定义连接池。 -
回调机制:钩子函数让业务逻辑与数据操作解耦,便于实现密码加密、日志记录等通用逻辑。
-
链式调用:直观的 API 设计降低使用成本,底层通过
Statement。
如果大家关于 go gorm 框架的源码解读还有哪些不清楚的地方,欢迎大家在评论区交流~~~
版权声明
未经授权,禁止转载本文章。
如需转载请保留原文链接并注明出处。即视为默认获得授权。
未保留原文链接未注明出处或删除链接将视为侵权,必追究法律责任!
本文原文链接: https://fiveyoboy.com/articles/go-source-code-gorm/
备用原文链接: https://blog.fiveyoboy.com/articles/go-source-code-gorm/