Go 原理之 GMP 并发调度模型(goroutine/processor/thread)
用过 Go 语言的开发者都知道,它的并发性能堪称“杀手锏”——只需一个 go 关键字就能轻松启动轻量级线程,支持数万级并发而不卡顿。
这背后的核心秘密,正是 Go 自有的 GMP 并发调度模型。
它通过巧妙协调 Goroutine(用户级线程)、Processor(逻辑处理器)和 Thread(操作系统线程)三者关系,在“轻量级”和“执行效率”之间找到了完美平衡。
今天,我们从原理到源码,彻底讲透 GMP 模型的设计逻辑。
一、为什么需要 GMP 模型?
在聊 GMP 之前,得先搞清楚一个问题:Go 为什么不直接用操作系统的线程调度,而是要自己搞一套调度模型?
这就需要从传统线程调度的痛点说起。
操作系统的线程(Thread)是内核级调度单位,重量大、切换成本高——每次切换需要陷入内核态,保存寄存器、内存映射等上下文信息,耗时通常在微秒级。
如果用线程实现高并发,比如启动 1 万个线程,频繁的内核态切换会让 CPU 大部分时间消耗在调度上,实际业务执行效率极低。
Go 为了解决这个问题,引入了用户级线程 Goroutine——它的创建成本仅几 KB 内存,切换在用户态完成,耗时纳秒级,支持轻松启动百万级实例。
但 Goroutine 终究要映射到操作系统线程上才能执行,如何高效管理“海量 Goroutine”与“有限 Thread”的映射关系?
这就是 GMP 模型的核心使命:通过 Processor 作为“中间桥梁”,实现 Goroutine 的高效调度与 Thread 的合理复用。
二、GMP 核心组件解析
GMP 模型的名字来源于三个核心组件的首字母:
G(Goroutine)、
M(Machine,对应操作系统线程,也就是 thread)、
P(Processor,逻辑处理器)。
三者分工明确又紧密协作,共同构成 Go 并发调度的基石。
我们结合 Go 源码(基于 Go 1.21 版本)逐一拆解。
一张图带你了解 GMP 的含义:

(一)G:Goroutine 轻量级执行体
G 是 Go 并发的最小执行单位,本质是“用户级线程”,我们用 go func() 启动的就是一个 G。
它比内核线程轻量的关键,在于上下文简单——仅包含程序计数器、栈指针和寄存器等核心执行信息,无需内核态资源。
go runtime 包自己实现的一种数据结构,存储执行时唯一的内存栈信息
源码中 G 的核心结构体(简化版):
// src/runtime/runtime2.go
type g struct {
// 1. 状态控制:决定 G 是否可调度(如运行中、就绪、阻塞)
status uint32 // G 的状态,如 _Gidle(空闲)、_Grunnable(就绪)、_Grunning(运行中)
stack stack // G 的栈信息(用户栈 + 系统栈)
sched gobuf // 上下文信息(程序计数器、栈指针等,切换时保存)
// 2. 调度关联:与 P、M 的绑定关系
m *m // 当前绑定的 M(执行该 G 的操作系统线程)
p *p // 当前绑定的 P(逻辑处理器)
nextp *p // 下一个要绑定的 P
schedlink guintptr // 用于挂载到就绪队列的链表节点
// 3. 其他关键信息
gopc uintptr // 创建该 G 的指令地址(定位 go 关键字位置)
startpc uintptr // G 执行的函数入口地址
waitreason waitReason // 阻塞原因(如等待锁、通道、IO 等)
}核心特点:
- 轻量:初始栈大小仅 2 KB,支持动态扩容(最大 1 GB);
- 用户态切换:上下文保存在
sched字段,切换时无需陷入内核; - 状态驱动:通过
status字段控制调度流程,核心状态包括就绪(_Grunnable)、运行中(_Grunning)、阻塞(_Gwaiting)。
(二)M:Machine 操作系统线程
M 是操作系统的内核线程(简称线程),是实际的“执行载体”——Goroutine 最终要通过 M 映射到 CPU 上执行。
Go 会通过 runtime 动态管理 M 的数量,既保证并发需求,又避免线程过多导致的切换开销。
- thread 线程,就是我们平时理解的线程,如果你不理解什么是线程,请参考文章 进程线程协程的概念和区别
源码中 M 的核心结构体(简化版):
// src/runtime/runtime2.go
type m struct {
// 1. 执行核心:与 P、G 的绑定关系
p *p // 当前绑定的 P(M 必须绑定 P 才能执行 G)
curg *g // 当前正在执行的 G
nextg *g // 下一个要执行的 G(预取优化)
// 2. 线程资源:内核线程相关信息
id int64 // 线程唯一标识
osThread uintptr // 对应操作系统线程的 ID(与内核交互用)
mstartfn func() // 线程启动时执行的函数
// 3. 调度辅助:与调度器的交互信息
schedlink muintptr // 用于挂载到 M 链表的节点
spinning bool // 是否处于“自旋”状态(主动寻找可执行的 G)
blocked bool // 是否处于阻塞状态
}核心特点:
- 内核态执行:M 是内核线程,由操作系统调度,但 Go runtime 会干预其管理;
- 绑定 P 才能执行 G:M 必须与一个 P 绑定,才能从 P 的就绪队列中获取 G 执行;
- 自旋机制:当 M 无 G 可执行时,会自旋一段时间寻找 G,避免频繁创建销毁线程。
(三)P:Processor 逻辑处理器
P 是 GMP 模型的“调度中枢/调度核心”,本质是“逻辑处理器”,它维护着一个“就绪 G 队列”,并负责将 G 分配给 M 执行。
P 的数量由环境变量 GOMAXPROCS 控制(默认等于 CPU 核心数),直接决定了 Go 程序的并发执行能力——因为同一时间,一个 P 只能绑定一个 M,一个 M 只能执行一个 G,所以 P 的数量就是“同时运行的 G 数量上限”。
processor 处理器,go runtime 包实现的调度器,主要用来并发调度 goroutine 协程的启动、执行、等待、暂停、销毁等生命周期
源码中 P 的核心结构体(简化版):
// src/runtime/runtime2.go
type p struct {
// 1. 调度队列:核心资源,存放就绪状态的 G
runq [256]g // 本地就绪队列(环形数组,无锁访问)
runqhead uint32 // 队列头指针
runqtail uint32 // 队列尾指针
runnext guintptr // 下一个优先执行的 G(局部调度优化)
// 2. 绑定关系:与 M、全局调度器的关联
m *m // 当前绑定的 M
id int32 // P 的唯一标识
status uint32 // P 的状态(如 _Pidle 空闲、_Prunning 运行中)
// 3. 资源管理:G 的栈缓存、内存分配缓存等
mcache *mcache // 内存分配缓存(避免多线程竞争全局内存)
stackcache [_NumStackOrders]stackfreelist // G 的栈缓存(复用栈空间,减少内存分配)
}核心特点:
- 就绪队列管理:每个 P 有独立的本地就绪队列(
runq),G 创建后先加入本地队列,避免全局队列竞争; - 资源缓存:维护内存和栈缓存,减少 G 创建销毁的资源开销;
- 调度中介:通过 P 实现 G 与 M 的解耦,让调度更灵活。
三、GMP 调度核心流程
那GMP 调度流程中:G 是如何被执行?
理解了 G、M、P 的角色后,关键要搞懂它们的协作流程——一个 G 从创建到执行完成,经历了哪些调度环节?
我们以“创建 Goroutine 并执行”为例,拆解完整调度链路。
比如我们使用 go 开启一个协程:
go func(){
// 开启协程,处理逻辑
}()‘go func()‘经历了哪些过程?

-
G 创建与入队当执行
go func()时,runtime 会调用newproc()函数创建一个 G 实例:- 初始化 G 的状态为
_Gidle,设置执行函数入口startpc; - 从当前 P 的栈缓存中分配栈空间;
- 将 G 的状态改为
_Grunnable,加入当前 P 的本地就绪队列(runq)。
- 初始化 G 的状态为
-
M 绑定 P 并获取 GM 要执行 G,必须先绑定一个空闲的 P:
- 若有空闲 M(如之前自旋的 M),则直接绑定一个空闲 P;
- 若无空闲 M,runtime 会调用
newm()函数创建新的操作系统线程(M),并绑定空闲 P; - M 绑定 P 后,从 P 的本地就绪队列(
runq)头部取出一个 G,将其状态改为_Grunning,并绑定到自己的curg字段,开始执行 G。
-
G 执行与状态切换G 执行过程中,会遇到多种场景导致状态变化,触发调度:
- 正常执行完成:G 执行完函数后,调用
goexit(),状态改为_Gdead,M 会从 P 的就绪队列中取下一个 G 执行; - 主动阻塞:若 G 调用
time.Sleep()、通道操作、锁操作等,会主动将状态改为_Gwaiting,并释放 M;M 会从 P 中取下一个 G 执行,被阻塞的 G 则等待唤醒(如睡眠时间到、通道有数据); - 被抢占:若 G 执行时间过长(超过 10ms),runtime 会触发“抢占式调度”,将其状态改为
_Grunnable,重新加入就绪队列,让其他 G 有机会执行。
- 正常执行完成:G 执行完函数后,调用
-
G 唤醒与重新调度被阻塞的 G 满足唤醒条件后(如
time.Sleep()结束),runtime 会将其状态改回_Grunnable,并根据情况加入队列:- 若当前有空闲 P,直接加入该 P 的本地就绪队列;
- 若无空闲 P,加入全局就绪队列,等待其他 P 空闲时“偷取”G 执行。
-
负载均衡:P 的偷取机制当一个 P 的本地就绪队列为空时,为了避免 M 空闲,会触发“偷取机制”:
- P 会先从全局就绪队列中获取一批 G;
- 若全局队列也为空,则从其他 P 的本地就绪队列中“偷取”一半的 G 到自己的队列中,实现负载均衡。
大白话讲解:
-
通过 ‘go func()’ 创建一个 goroutine(数据结构,有个唯一 gid,以及内存栈信息),这里称为:G
-
有两个存储 G 的队列(本地P队列,全局队列),新创建的 G 会优先加入本地 P 队列中,如果满了就会保存在全局队列中
-
G 最终会通过 P 调度运行在 M 中,MP 是组合(一个M必须持有一个P,M:P=1:1)
-
M 会从 P 的队列中弹出一个可执行的 G 来执行,如果没有,则会从全局队列中获取,全局队列也没有,则会从其他 MP 队列中偷取一个 G执行,从其他 P 偷的方式称为 work stealing
-
一个 M 调度 G 执行是一个循环过程
-
当 M 执行 G 过程中发生 systemCall 阻塞,M 会阻塞,如果当前有一些 G 在执行,runtime 会把这个线程 M 从 P 中摘除(detach),此时 P 会和 M 解绑即 hand off,然后再创建/从休眠队列中取一个 M 来服务这个 P
-
系统调用(如文件IO)阻塞(同步):阻塞MG,M与P解绑
-
网络 IO 调用阻塞(异步):G 移动到NetPoller,M 继续执行 P 中的 G
-
mutex/chan阻塞(异步):G 移动到 chan 的等待队列中,M 继续执行 P 中的 G
- 当 M 系统调用结束后进入休眠/销毁状态,这个 G 会尝试获取一个空闲的 P 执行,如果没有,这个 G 会放入全局队列
如图:

抢占式调度:
M 每隔约 10ms 会切换一个 G,被切换的 G 会重新回到本地P队列
如果在 Goroutine 去执行一个 sleep 操作,导致 M 被阻塞了。
Go 程序后台有一个监控线程 sysmon,它监控那些长时间运行的 G 任务然后设置可以强占的标识符,别的 Goroutine 就可以抢先进来执行。
源码及注释如下:
Go 1.14 之后引入的“抢占式调度”是保障公平性的关键——避免单个 G 长期占用 CPU 导致其他 G 饥饿。
其核心实现在 src/runtime/preempt.go 中,简化源码及注释如下:
// 检查当前 G 是否需要被抢占
func preempt() bool {
g := getg() // 获取当前执行的 G
m := g.m // 获取当前绑定的 M
p := m.p // 获取当前绑定的 P
// 1. 若 G 执行时间超过 10ms(抢占阈值),触发抢占
if g.startTime.Add(10 * time.Millisecond).Before(mclock()) {
return true
}
// 2. 若 P 有更高优先级的 G 等待,触发抢占
if p.runnext != 0 || p.runqhead != p.runqtail {
return true
}
return false
}
// 执行抢占逻辑:将当前 G 置为就绪状态,重新调度
func preemptone(p *p) {
// 1. 找到绑定 P 的 M
m := p.m
if m == nil || m.curg == nil {
return
}
// 2. 获取当前执行的 G,并修改状态为就绪
g := m.curg
casgstatus(g, _Grunning, _Grunnable) // 原子修改状态,避免竞争
// 3. 将 G 重新加入就绪队列
runqput(p, g, false)
// 4. 触发 M 重新调度,取下一个 G 执行
m.preempted = true
goready(g, 0)
}核心逻辑:runtime 会通过定时器检查每个运行中的 G,若执行时间超过 10ms 或有更高优先级 G 等待,就将其状态改为就绪并重新入队,让 M 切换执行其他 G,保证调度公平性。
四、观察 GMP 调度行为
光看原理不够直观,我们通过一段实战代码,结合 runtime 包的工具函数,观察 GMP 调度的实际行为——比如 P 的数量、G 的创建与执行、M 的自旋状态等。
实战代码:并发任务与调度信息打印:
package main
import (
"fmt"
"runtime"
"sync"
"time"
)
// 任务函数:模拟耗时操作
func task(id int, wg *sync.WaitGroup) {
defer wg.Done()
// 打印当前 G、M、P 的信息
gID := getGID() // 自定义函数:获取当前 G 的 ID
mID := runtime.ThreadID() // 获取当前 M 的 ID(Go 1.16+ 支持)
pID := getPID() // 自定义函数:获取当前 P 的 ID
fmt.Printf("任务 %d:G=%d, M=%d, P=%d 开始执行\n", id, gID, mID, pID)
// 模拟耗时操作(触发调度)
time.Sleep(100 * time.Millisecond)
fmt.Printf("任务 %d:G=%d, M=%d, P=%d 执行完成\n", id, gID, mID, pID)
}
// 自定义函数:通过反射获取当前 G 的 ID
func getGID() uint64 {
var gID uint64
// 反射获取 g 结构体中的 id 字段
runtime_procPin() // 锁定当前 M 到 P,避免调度
defer runtime_procUnpin()
g := getg() // 获取当前 G(内部函数,需通过反射调用)
gID = g.goid
return gID
}
// 自定义函数:通过反射获取当前 P 的 ID
func getPID() int32 {
runtime_procPin()
defer runtime_procUnpin()
p := getg().m.p // 获取当前 M 绑定的 P
return p.id
}
// 导入内部函数(需通过链接器指定)
//go:linkname getg runtime.getg
func getg() *g
//go:linkname runtime_procPin runtime.procPin
func runtime_procPin()
//go:linkname runtime_procUnpin runtime.procUnpin
func main() {
// 1. 设置 P 的数量(默认等于 CPU 核心数,这里手动设置为 2)
runtime.GOMAXPROCS(2)
fmt.Printf("当前 P 的数量:%d\n", runtime.GOMAXPROCS(0))
// 2. 启动 5 个 Goroutine 执行任务
var wg sync.WaitGroup
wg.Add(5)
for i := 1; i <= 5; i++ {
go task(i, &wg)
}
wg.Wait()
fmt.Println("所有任务执行完成")
}
// 定义 g 结构体(仅用于反射获取字段)
type g struct {
goid uint64
// 其他字段省略(仅需 goid 字段)
}执行结果与调度分析:
执行结果(示例,G、M、P 编号可能不同):
调度行为分析:
- P 数量固定为 2(由
GOMAXPROCS(2)设置),同一时间最多有 2 个 G 并行执行; - 5 个 G 由 2 个 M 执行(M 编号 140700、140701),每个 M 绑定一个 P,交替执行多个 G;
- 当 G 执行
time.Sleep()阻塞时,M 会从 P 的就绪队列中取下一个 G 执行,实现 M 的复用。
五、大白话总结 GMP
大白话:减少/避免 CPU 频繁创建线程的高成本开销,最大化的利用线程、CPU 的执行能力
不是 “减少创建线程” 这么简单,而是用 “轻量的协程 (G)” 替代大量的系统线程 (M),再通过 P 这个 “调度员” 把成千上万个 G 合理分配给少量的 M 去执行,让 CPU 核心(对应 P 的数量)始终有活干,既避免线程创建 / 切换的高成本,又把 CPU 的算力榨到极致。
拆解成更通俗的 “打工人” 例子(彻底懂透)
咱们把 GMP 对应成现实场景,一看就明白:
- CPU 核心:公司里的工位(比如 2 个工位 = 双核),工位数量固定,是干活的 “硬件资源”;
- M(系统线程):公司里的正式员工,招聘 / 辞退成本高(对应线程创建 / 销毁开销大),一个员工同一时间只能坐一个工位干活;
- P(处理器):工位的 “工牌”,只有拿到工牌的员工(M 绑定 P)才能在工位上干活,工牌数量 = 工位数量(默认等于 CPU 核心数);
- G(协程):待处理的零散任务(比如打印文件、整理数据),创建 / 交接成本极低(几 KB 内存),可以有上千上万个。
你的理解 “减少 CPU 频繁创建线程,最大化利用线程执行”,对应到例子里就是:
- 公司不会为了上千个零散任务(G)招聘上千个正式员工(M)(减少线程创建);
- 只招少量员工(M,数量≈工位 / P 数量),让这些员工拿着工牌(P)在工位上,不停接手新的零散任务(G)干(最大化利用线程执行);
- 要是某个员工(M)处理的任务(G)卡住了(比如等打印机 = IO 阻塞),他的工牌(P)会立刻交给另一个空闲员工,继续干活,不会让工位空着(CPU 不闲置)。
六、避坑点
理解 GMP 模型不仅能帮我们看懂原理,更能解决实际开发中的并发问题。
以下是开发中高频遇到的 GMP 相关坑点及解决方案。
避坑点 1:滥用 GOMAXPROCS 调优
很多开发者认为“将 GOMAXPROCS 设置为 CPU 核心数的 2 倍能提升性能”,这是误区——GMP 模型默认已将 GOMAXPROCS 设为 CPU 核心数,此时 P 的数量与 CPU 核心数匹配,能最大限度减少线程切换开销。
反例:在 4 核 CPU 上设置 GOMAXPROCS(8),会导致 P 的数量超过 CPU 核心数,M 数量随之增加,内核态切换开销增大,反而降低性能。
解决方案:除非是“IO 密集型”场景(如大量网络请求、文件读写),且线程经常阻塞等待 IO,可适当调大 GOMAXPROCS;否则保持默认值即可。
避坑点 2:Goroutine 泄漏导致资源耗尽
GMP 模型中,Goroutine 若长期处于阻塞状态(如忘记关闭的通道接收、未超时的锁等待),会导致 G 无法被回收,逐渐积累耗尽内存。
// 错误示例:Goroutine 泄漏
func leakDemo() {
// 无缓冲通道,发送后无人接收,G 一直阻塞
ch := make(chan int)
go func() {
ch <- 1 // 发送后阻塞,G 状态为 _Gwaiting,无法回收
}()
// 忘记接收通道数据,也未关闭通道
}解决方案:
- 给阻塞操作设置超时(如
time.After()结合通道); - 使用可关闭的通道,确保发送方或接收方能正常关闭;
- 用
runtime.NumGoroutine()监控 Goroutine 数量,排查泄漏。
避坑点 3:忽视 M 的自旋机制导致资源浪费
当 P 无 G 可执行时,M 会自旋一段时间(默认 1ms)寻找 G,若仍无 G 则进入休眠。
若程序中存在大量“短时间空闲”的场景,自旋的 M 会占用 CPU 资源。
解决方案:对于“长时间无 G 可执行”的场景(如服务空闲期),可通过监控 runtime.NumThread() (M 的数量),结合业务逻辑触发 M 休眠,减少资源占用。
常见问题
Q1. 什么是M0 & G0 ?
M0 & G0 的启动
go 启动的时候,默认会启动 M0 线程 和 G0 协程
M0:编号为 0 的主线程
GO:编号为 0 的主协程
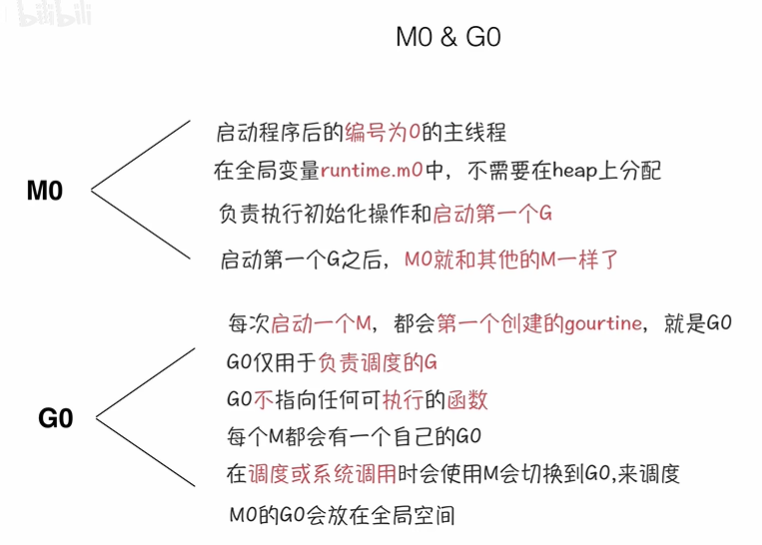
Q2. 协程 goroutine 的调度策略
-
队列轮转:
P 会周期性的将G调度到M中执行,执行一段时间后,保存上下文,将 G 放到队列尾部,然后从队列中再取出一个G进行调度
除此之外,P还会周期性的查看全局队列是否有G等待调度到M中执行
-
系统调度:
当 G0 即将进入系统调用时,M0 将释放 P,进而某个空闲的 M1 获取 P,继续执行 P 队列中剩下的 G。
M1 的来源有可能是 M 的缓存池,也可能是新建的
当 G0 系统调用结束后,如果有空闲的P,则获取一个P,继续执行 G0。如果没有,则将 G0 放入全局队列,等待被其他的 P 调度。然后 M0 将进入缓存池睡眠
-
抢占式调度:
sysmon 监控协程,如果 g 运行时间过长
10 ms,那会发送信号给到 m,g 会被挂起,m继续执行 p 中的 g,防止其他 g 被饿死
Q3. 协程的生命周期
创建、等待(调用 gopark 进入等待状态)、唤醒执行(调用 goready 唤醒等待的 g 执行)、销毁
Q4. G、M、P 的数量
G 的初始化大小是 2-4 k,具体数量由内存决定,
P 的数量由用户设置的 GoMAXPROCS 决定,等于CPU的核心数,但是不论 GoMAXPROCS 设置为多大,P 的储存G的数量最大为 256
M 默认限制 10000
Q5. Golang 为什么要创建 goroutine 协程
轻量:1.大小只有 2-4 k,用户级线程,减少了内核态切换创建的开销
操作系统中虽然已经有了多线程、多进程来解决高并发的问题,但是在当今互联网海量高并发场景下,对性能的要求也越来越苛刻,大量的进程/线程会出现内存占用高、CPU消耗多的问题,很多服务的改造与重构也是为了降本增效。
一个进程可以关联多个线程,线程之间会共享进程的一些资源,比如内存地址空间、打开的文件、进程基础信息等,每个线程也都会有自己的栈以及寄存器信息等,线程相比进程更加轻量,而协程相对线程更加轻量,多个协程会关联到一个线程,协程之间会共享线程的一些信息,每个协程也会有自己的栈空间,所以也会更加轻量级。从进程到线程再到协程,其实是一个不断共享,减少切换成本的过程。
Golang 使用协程主要有以下几个原因:
● 大小
协程大概是2-4k,线程大概是1m
● 创建、切换和销毁
协程是用户态的,由 runtime 创建和销毁,没有内核消耗,线程是内核态的,与操作系统相关,创建和销毁成本较高
Q6. 什么是 CSP 并发模型?
CSP 并发模型:不要以共享内存的方式来通信,而以通信的方式来共享内存
go 实现 CSP 并发模式是通过: goroutine + chan
Q7. G 调度执行中断是如何恢复的?
G 是一个数据结构,存储上下文堆栈信息
中断的时候将寄存器里的栈信息,保存到自己的 G 对象(sudog)里面。
当再次轮到自己执行时,将自己保存的栈信息复制到寄存器里面,这样就接着上次之后运行了。
Q8. 当 G 阻塞时,g、m、p 会发生什么
G 的状态会从运行态变为阻塞态,放入 P 等待队列
M 会从该 Goroutine 所在的 P 中分离出来,转而执行其他 Goroutine
P 会从该 Goroutine 所在的 M 中分离出来,将该 Goroutine 放入等待队列中,并从空闲的 M 队列中取出一个 M,将其绑定到该 P 上
Q9. runtime 是什么?
golang 底层的基础设施:
-
GMP 的创建和调度
-
内存分配
-
GC
-
内置函数如 map,chan,slice,反射的实现等
-
pprof,trace,CGO
-
操作系统以及 CPU 的一些封装
-
….
基本上就是 go 的底层所在了

Q10. 怎么启动第一个 goroutine?
main 启动函数会默认启动 G0 协程
Q11. Go 的协程为什么那么好,与线程的区别
● 大小
协程大概是 2k-4k,线程大概是1m
● 创建、切换和销毁
协程是用户态的,由runtime创建和销毁,没有内核消耗,线程是内核态的,与操作系统相关,创建和销毁成本较高
提高cpu的利用率,解决了高消耗的CPU调度,用户态的轻量级的线程,约4k
减少了内核切换成本,操作系统分为用户态和内核态(表示操作系统底层)

Q12. 线程与协程的区别
一个线程有多个协程,协程是用户态的轻量级的线程,非抢占式的,由用户控制,没有内核切换的开销
核心区别在“调度粒度”和“灵活性”:
传统线程池是“内核线程 + 任务队列”,任务切换是内核态切换,开销大;
GMP 是“用户级 Goroutine + 逻辑 P + 内核 M”,G 切换是用户态,且通过 P 的偷取机制实现负载均衡,灵活性更高,支持百万级并发。
Q13. 为什么 P 的数量决定了并发执行的 G 数量上限?
因为“一个 P 同一时间只能绑定一个 M,一个 M 同一时间只能执行一个 G”——P 是“逻辑处理器”,对应 CPU 的“执行上下文”,同一时间一个 CPU 核心只能执行一个线程(M),所以 P 的数量(默认等于 CPU 核心数)就是“同时运行的 G 数量上限”,超过的 G 会在就绪队列中等待。
Q14. Go 中的 Goroutine 可以设置优先级吗?
目前 Go 官方不支持直接设置 Goroutine 优先级,但可通过“调度暗示”间接实现:比如将高优先级任务的 G 放入 P 的 runnext 字段(优先执行队列),或通过控制 G 的创建顺序和阻塞时机,让高优先级任务先执行。
Go 团队计划在未来版本中引入正式的优先级调度。
Q15. 抢占式调度能解决所有 G 饥饿问题吗?
大部分场景可以,但有特殊情况:比如 G 执行的是“无函数调用的纯循环”(如 for {}),在 Go 1.14 之前无法被抢占,会导致其他 G 饥饿;Go 1.14 之后通过“信号中断”解决了该问题,即使是纯循环也能被抢占,基本避免了饥饿问题。
总结
GMP 模型是 Go 并发性能的“核心引擎”,其设计精髓在于三点:
- 轻量执行体:Goroutine 以用户态线程为基础,大幅降低创建和切换开销。
- 中间调度层:Processor 作为 G 和 M 的中介,通过本地队列和偷取机制实现负载均衡。
- 高效调度策略:抢占式调度保证公平性,自旋机制减少线程创建销毁开销。
开发中,我们不需要手动管理 G、M、P 的生命周期,但理解 GMP 模型能帮我们写出更高效的并发代码:比如避免 Goroutine 泄漏、合理设置 GOMAXPROCS、利用调度特性优化任务执行顺序。
如果大家关于 Go GMP 模型的解读还有哪些不清楚的地方,欢迎大家在评论区交流~~~
版权声明
未经授权,禁止转载本文章。
如需转载请保留原文链接并注明出处。即视为默认获得授权。
未保留原文链接未注明出处或删除链接将视为侵权,必追究法律责任!
本文原文链接: https://fiveyoboy.com/articles/go-goroutine-gmp/
备用原文链接: https://blog.fiveyoboy.com/articles/go-goroutine-gmp/